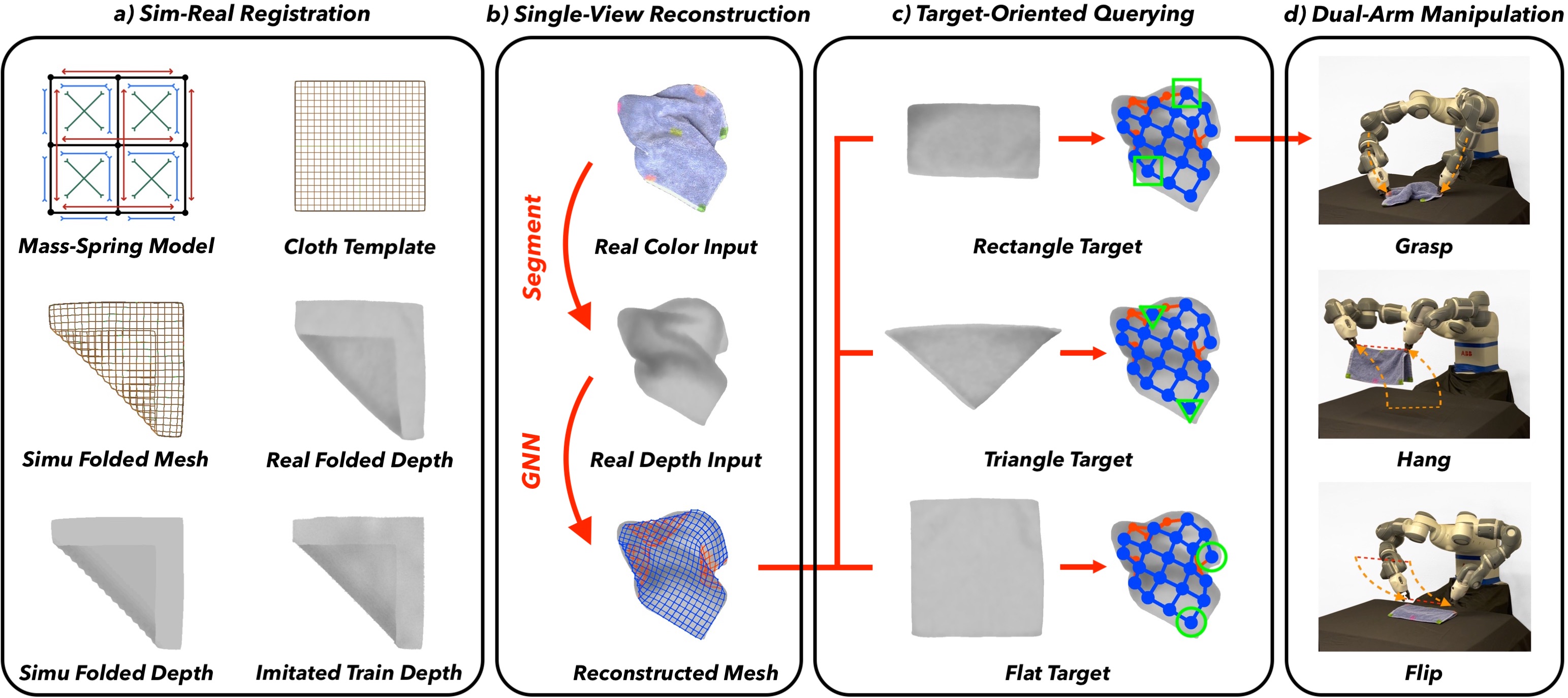
TRTM System: a) Sim-real registration of one real-world cloth to a synthetic cloth mesh with imitated top-view observations.
b) Single-view template-based reconstruction of one randomly crumpled cloth from its top-view depth observation only.
c) Querying the best visible vertex pair according to different target configurations: flat, triangle, and rectangle.
d) Dual-arm manipulation using one ABB YuMi Robot at the selected vertex pair with optimized grasp-hang-and-flip trajectories.
Abstract
Precise reconstruction and manipulation of the crumpled cloths is challenging
due to the high dimensionality of cloth models, as well as the limited observation at self-occluded regions.
We leverage the recent progress in the field of single-view human reconstruction to template-based reconstruct
crumpled cloths from their top-view depth observations only, with our proposed sim-real registration protocols.
In contrast to previous implicit cloth representations, our reconstruction mesh explicitly describes the positions and visibilities of the entire cloth mesh vertices,
enabling more efficient dual-arm and single-arm target-oriented manipulations.
Experiments demonstrate that our TRTM system can be applied to daily cloths that have similar topologies as our template mesh,
but with different shapes, sizes, patterns, and physical properties.
Paper Video
Template-based Reconstruction
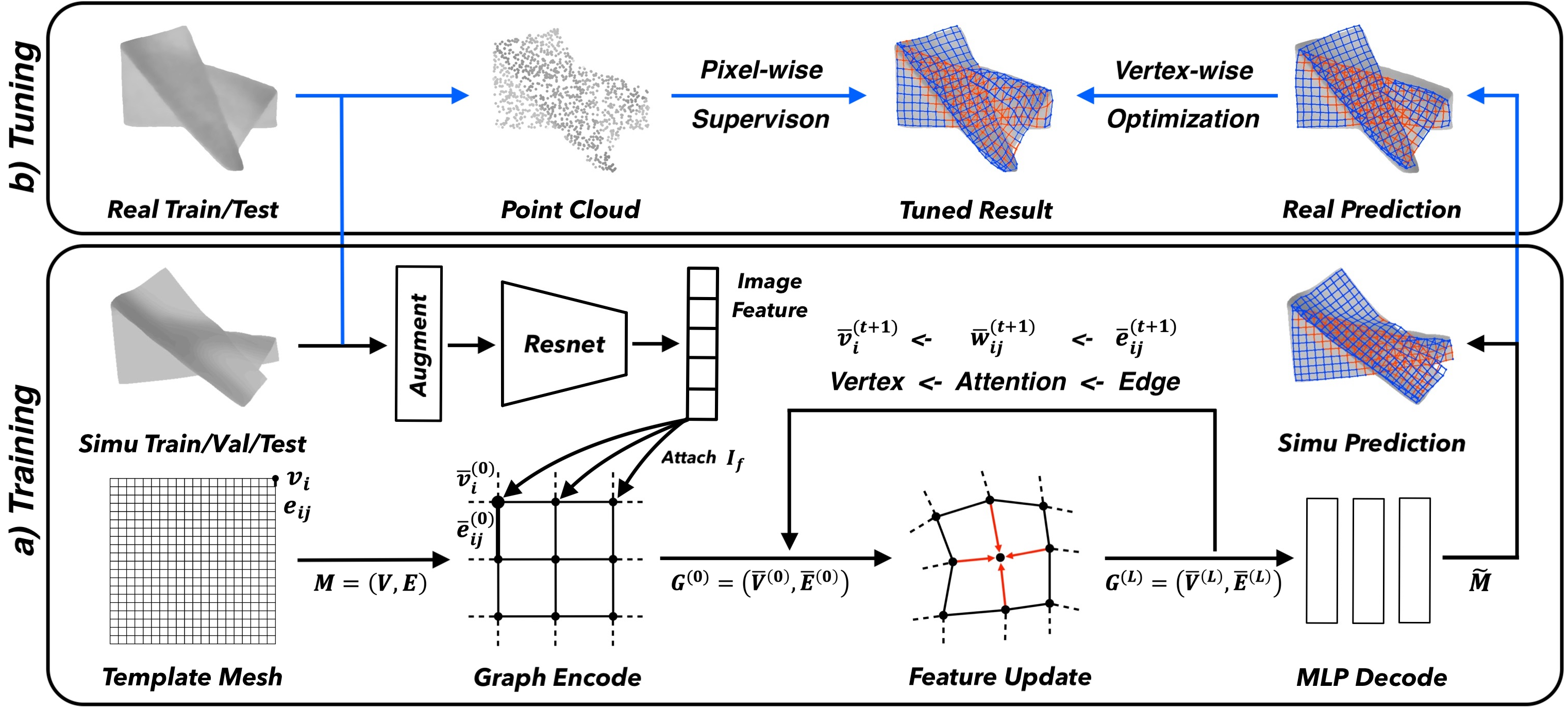
Template-based GNN. a) Synthetic training with simulated cloth meshes and depth images.
From left to right: synthetic cloth dataset and template mesh, image feature encoding and template graph encoding,
graph feature updating with attention message flow, mesh decoding.
b) Real-world tuning with collected cloth configurations and depth observations.
From left to right: real-world cloth dataset, point cloud observation, pixel-wise tuned result from the GNN prediction.
Within the simulation: we demonstrate different state representations of the Known randomly dragged, folded, and dropped cloths:
Implicit top-view color image and depth image vs. Explicit reconstructed mesh and clustered group.
We decode each feature graph during the 15 GNN regression to demonstrate the "expanding" process of our template mesh.
We achieve on average 1.22cm vertex-wise loss, 5.8% silhouette and 0.73cm chamfer difference with this cloth.
Within the real-world: we demonstrate different state representations of the Unknown randomly dragged, folded, and dropped cloths:
Implicit top-view color image and depth image vs. Explicit reconstructed mesh and clustered group.
We decode each feature graph during the 15 GNN regression to demonstrate the "expanding" process of our template mesh.
Template real square cloth: 0.3m x 0.3m size, blue color, keypoint labeled, 5mm thickness.
We achieve on average 1.73cm vertex-wise loss, 8.1% silhouette and 0.96cm chamfer difference with this cloth.
We achieve on average 2.09cm vertex-wise loss, 9.2% silhouette and 1.04cm chamfer difference with this cloth.
Rectangle T-shirt: 0.3m x 0.4m size, star-patterned color, keypoint labeled, 6mm thickness, two-layered bodies and sleeves.
We achieve on average 2.67cm vertex-wise loss, 11.3% silhouette and 1.49cm chamfer difference with this cloth.
Dual-arm Manipulation
Within the real-world: we demonstrate different state representations of the Unknown randomly dragged, folded, and dropped template square cloths within the operation region.
From the reconstructed cloth meshes and clustered mesh groups, we execute the target-oriented querying with dual-arm manipulation for flat, triangle, and rectangle targets.
The maximum dual-arm operation episode is set as two for flat target and only one for triangle and rectangle targets, during which the cloth meshes can still be tracked before and after each dual-arm grasp-hang-flip operation.
Randomly one-time dragged template square cloths: dual-arm grasp-hang-flip to flat, triangle, and rectangle targets.
We achieve on average 98.2% coverage value for the flat target with two flipping operations;
While 85.9% and 82.6% top-view similarities for the triangle and rectangle targets with only one flipping operation.
Randomly two-times folded template square cloths: dual-arm grasp-hang-flip to flat, triangle, and rectangle targets.
We achieve on average 97.1% coverage value for the flat target with two flipping operations;
While 81.25% and 78.6% top-view similarities for the triangle and rectangle targets with only one flipping operation.
Randomly one-time dropped template square cloths: dual-arm grasp-hang-flip to flat, triangle, and rectangle targets.
We achieve on average 97.4% coverage value for the flat target with two flipping operations;
While 86.3% and 85.7% top-view similarities for the triangle and rectangle targets with only one flipping operation.
Within the real-world: we demonstrate the generalization ability of our square TRTM system to other daily cloths (smaller rectangle, larger square, T-shirt) from the above Template-based Reconstruction section.
The maximum dual-arm operation episode is set as two for flat target and only one for triangle and rectangle targets, during which the cloth meshes can still be tracked before and after each dual-arm grasp-hang-flip operation.
Randomly one-time dropped rectangle cloth, larger square cloth, and T-shirt: with flat, triangle, and rectangle targets.
Single-arm Manipulation
Within the real-world: we demonstrate different state representations of the Unknown randomly dragged, folded, and dropped template square cloths within the operation region.
From the reconstructed cloth meshes and clustered mesh groups, we execute the target-oriented querying with single-arm manipulation for flat target.
The maximum single-arm operation episode is set as four for flat target, during which the cloth meshes can still be tracked before and after each single-arm grasp-drag operation.
Randomly dragged, folded, and dropped template square cloths: single-arm grasp-drag the farthest visible group vertex to its locally flat target position (as shown in orange).
We achieve on average 92.3%, 82.3%, and 78.5% coverage values for the flat target with the randomly dragged, folded, and dropped template cloths after four dragging operations.